Как мы переработали обработку документов и ускорили флоу на 24%
Новая версия интерфейса не прижилась: сотрудники тратили больше времени, не доверяли системе и возвращались к локальным папкам. В этом кейсе я показываю, как мы пересобрали процесс вокруг реальных задач пользователей, проверили решение на тестах и ускорили базовый сценарий на ~24%.
Компания
Банк ДОМ.РФ
Направление
Внутрений продукт
Тип
Web
Год
2025

Контекст
Что за досье клиентов?
Банк ДОМ.РФ — ипотечно-строительный банк. Я работала продуктовым дизайнером в команде, отвечающей за сервисы проектного финансирования застройщиков.
Банк сопровождает строительство на всём жизненном цикле проекта: проверяет документы, контролирует ход работ и анализирует риски. Застройщики регулярно отчитываются о статусе проекта и запрашивают транши. Каждый такой цикл сопровождается сотнями документов: акты, отчёты, проектная документация, подтверждения оплат, заявки на транши. Ошибка или потерянный файл напрямую влияет на сроки финансирования и деньги банка.
Около 25% документов подгружается автоматически в электронное досье из другой системы. Остальная часть хранится локально и обрабатывается сотрудниками вручную.

Первая попытка цифровизации не сработала
Обработка каждого файла вручную превращалась в квест: объединить → переименовать → проверить версию → разложить по папкам → сохранить копии для экспертов.
Чтобы упростить работу сотрудников и сократить количество ошибок и простоев, команда продукта разработала модуль обработки документов в досье. Гипотеза была простой: сотруднику достаточно заполнить базовые атрибуты документа, а система автоматически распределит файлы и уберёт ручную сортировку.

Идея выглядела логичной, но после тестирования сотрудники остались недовольны:
«Теперь мы тратим больше времени, чем при ручной обработке по папкам»
«Интерфейс ощущается сложным и неудобным»
В результате эту версию не стали выводить в прод. Меня подключили, чтобы разобраться в причинах провала, привести UX в порядок и сделать систему, в которую сотрудники захотят перейти из папок.
Задача
Цель бизнеса
Снизить трудозатраты сотрудников за счёт сокращения ручных операций при загрузке и классификации документов, а также уменьшить количество ошибок, потерь файлов и повторных запросов к застройщикам.
Миссия команды
Упростить массовую обработку документов: убрать лишние действия, автоматизировать рутину. Сделать интерфейс, который реально экономит время, чтобы сотрудники не хотели вернуться в локальные папки.
Кто будет пользоваться
Сотрудники отдела клиентского сопровождения корпоративного бизнеса. Они ежедневно получают документы от застройщиков в разных состояниях — от аккуратных пдф до криво названных сканов.
Критерии успеха
Сокращение времени обработки одного пакета документов
Снижение количества ошибок и повторных запросов к застройщикам
Рост готовности сотрудников использовать систему вместо локальных папок
Дискавери
Первым делом я разобрала весь процесс: требования, интерфейс, сценарий работы и обратную связь. Моя цель была — понять, почему MVP провалился и что снижает скорость работы сотрудников.
Аудит текущего интерфейса
Первые макеты рисовали аналитики в пэинте 👀 и о цельном сценарии там и речи не было.
Поэтому я погрузилась в требования к разработке, пообщалась с командой и покликала тестовый стенд. Разложила действия по шагам и собрала флоу. И сразу стало видно, где процесс тормозит сотрудников.
После загрузки файлов обязательно надо нажать на следующий шаг, чтобы перейти к обработке. Это лишняя трата времени и когнитивная нагрузка.
Для группировки файлов требуется дважды выбирать их чекбоксами: сначала в реестре, затем в модальном окне. При большом количестве файлов это превращается в рутину.

Заполнение атрибутов вынесено в отдельный шаг, где файлы снова нужно выбирать для массовых действий. Одни и те же операции повторяются несколько раз.
Сохраненные атрибуты нельзя отредактировать, только перезаполнять все поля.
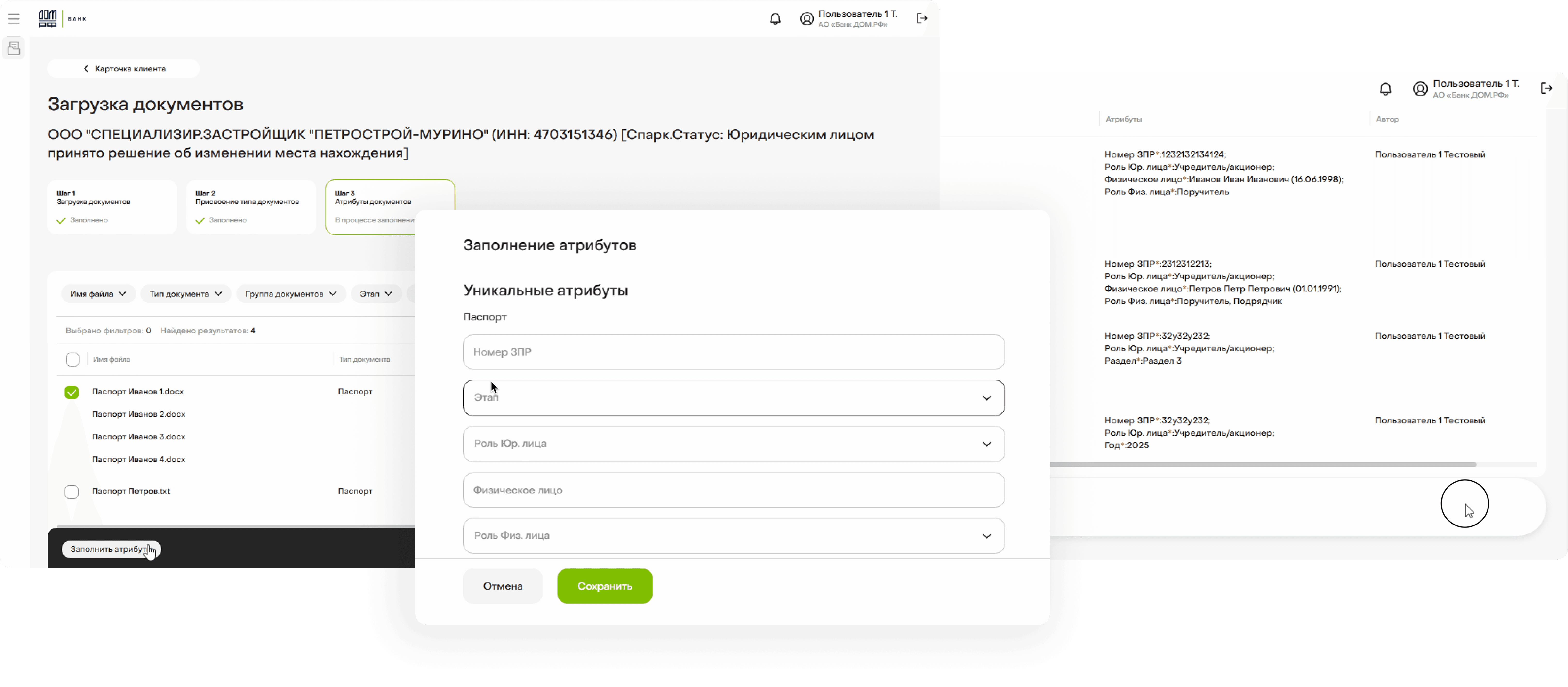
Для заполнения атрибутов нужно перейти на следующий шаг и снова проставить чек-боксы у файлов для множественного заполнения. Опять повтор действий.
Сохраненные атрибуты нельзя отредактировать, только перезаполнять все поля.
Что говорят пользователи
Ранее команда провела приемку тестового стенда с 10 сотрудниками-пользователями. Я собрала всю обратную связь, сгруппировала по темам и сопоставила со своим анализом.
Большая часть проблем полностью совпала с моими наблюдениями, что подтвердило корректность аудита. Дополнительно сотрудники указали на следующие сложности:
Нельзя массово заполнить файлы с одним типом и разными атрибутами
Нет предпросмотра файлов и тяжело определить файл, так как названия хаотичны
Неудобно считывать атрибуты в реестре
Структура данных
Вся суть обработки документов: выбираешь тип → появляются атрибуты (поля) под этот тип. Я собрала маппинг типов и атрибутов, чтобы понять, какой максимальный размер формы может быть.

Всего типов больше 500, а в одном типе может быть до 20 полей. Чаще всего атрибуты заполняются массово, но при этом часть полей общая, а часть — уникальная для разных типов.
То есть предугадать длину формы невозможно… А значит главное — сделать так, чтобы интерфейс мог выдерживать разные сценарии массовой и индивидуальной обработки.
Проработка концепции
После дискавери стало понятно, что проблема не в отдельных экранах, а в логике процесса целиком. Нужна была новая структура, которая поможет решать реальные задачи сотрудников и выдержит работу с большими объёмами документов.
Задачи пользователей
Я сформулировала ключевые задачи (JTBD в упрощенной форме), с которыми сотрудники приходят в систему, и использовала их как основу для проектирования нового процесса.
Массово заполнять атрибуты без повторения одних и тех же действий
Заполнять атрибуты по отдельности для файлов одного типа (например, несколько паспортов)
Быстро понимать, что находится внутри файлов с хаотичными названиями
Легко группировать файлы в один документ
Сразу видеть ошибки загрузки и статус обработки, чтобы не перепроверять вручную
Быстро просматривать заполненные атрибуты и редактировать данные
Поиск композиции
Интерфейс должен упрощать и ускорять работу сотрудников, поэтому композиция здесь играет ключевую роль. Она должна быть удобна для массовой загрузки, обработки и группировки файлов. Но главное — нужно отойти от пошагового сценария с постоянными переходами и модалками.
Досье клиентов — модуль большого личного кабинета, поэтому новый интерфейс должен быть консистентен с другими разделами и соответствовать дизайн-системе. В других модулях я заметила двухколоночную компоновку, которая на первый взгляд идеально подходила под нашу задачу.

Дополнительно я изучила внешние сервисы обработки файлов — конвертировщики, облачные хранилища и drag&drop-интерфейсы. Они помогли мне погрузиться в паттерны работы с большими потоками файлов.
Эволюция концепта
Работа над концепцией шла итерационно. Я пробовала разные варианты двухколоночной структуры, собирала быстрые low-fi решения и обсуждала их с командой.
На ранних этапах я рассматривала, например, вариант с рабочей областью для заполнения атрибутов слева и загруженными файлами справа в виде «буфера». Однако такой подход не решал ключевую задачу — массовое заполнение атрибутов.
В другом варианте поля для заполнения располагались и под файлами, и в правой панели, но это приводило к дублированию функционала и расфокусу пользователей.




В итоге я перенесла заполнение атрибутов в единую правую панель, а файлы, группы и структуру заполненных атрибутов — в левую. Чтобы закрыть задачу быстрого атрибутирования нескольких файлов одного типа, я предложила добавить два режима работы: массовый и по отдельности.

Мы решили прорабатывать дальше этот вариант, так как он удовлетворяет большинство потребностей.
Гипотезы
В результате дискавери и проработки концепции у нас появилась базовая гипотеза, вокруг которой строится всё дальнейшее решение.
Базовая гипотеза
Если объединить процесс обработки документов в одном экране, разделив его на две колонки (слева — файлы, справа — атрибуты), то мы ускорим работу пользователям и снизим когнитивную нагрузку, потому что сотруднику не придётся переключаться между шагами и модальными окнами.
Мы сформулировали набор продуктовых гипотез, которые отражают ключевые пользовательские боли и направления решения. Чтобы проверить жизнеспособность этих гипотез, я собрала low-fi концепты.
Гипотеза 1. Режимы заполнения
Если разделить сценарии массового и точечного заполнения атрибутов, то сотрудники смогут быстрее обрабатывать документы, потому что каждый режим будет оптимизирован под свой тип задачи и избавит от лишних ручных действий.

Гипотеза 2. Управление данными
Если в режиме по отдельности дать пользователю гибкий контроль над введенными значениями, то количество ошибок при заполнении снизится, потому что сотрудники смогут управлять значениями полей под свои задачи без риска потери информации.

Гипотеза 3. Действия над файлами
Если дать возможность управлять файлами как по одному, так и массово, то сотрудники смогут эффективнее работать с большим потоком документов, потому что все ключевые действия будут доступны в одном контексте без лишних переходов.

Гипотеза 4. Drag&drop-группировка файлов
Если позволить группировать файлы с помощью drag&drop, то сотрудники будут работать быстрее и интуитивнее, потому что сценарий повторяет привычную для пользователей «папочную» логику взаимодействия с файлами.
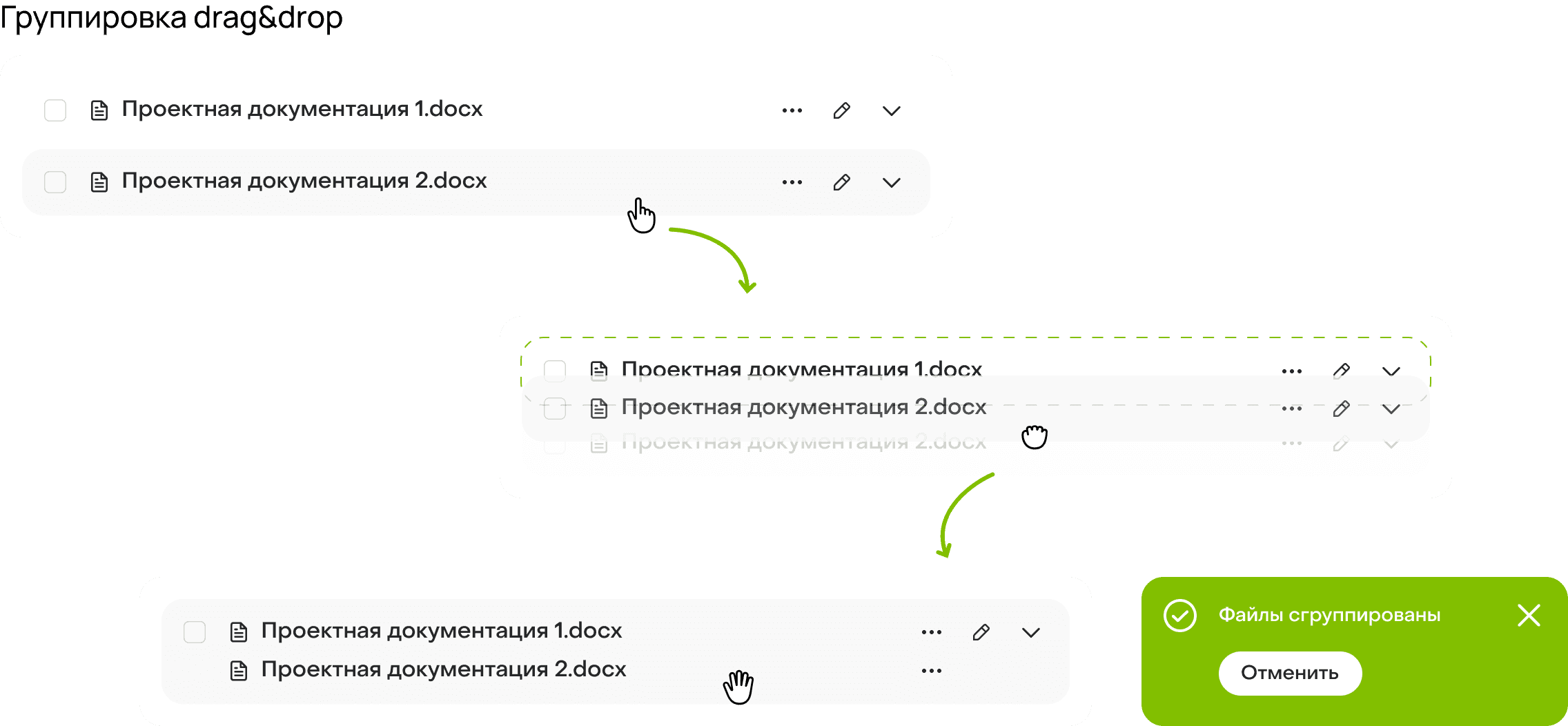
Гипотеза 5. Контроль ошибок
Если явно показывать файлы с ошибками, то работа с документами станет прозрачнее и быстрее, потому что сотрудникам не придётся вручную проверять, какие файлы не были загружены.

Гипотеза 6. Прогресс заполнения
Если показывать прогресс заполнения атрибутов файлов, то сотрудникам будет лучше ориентироваться в процессе обработки, потому что они будут видеть текущее состояние задачи и объём оставшейся работы.

Приоритизация и скоуп
После формирования продуктовых гипотез мы перешли к определению скоупа первой итерации. Нам было важно определить, какие механики дадут максимальный эффект уже в первой итерации, не перегружая при этом интерфейс и разработку.
Для приоритизации все гипотезы мы оценили по двум параметрам:
Value — влияние на скорость обработки документов и снижение ошибок пользователей
Effort — сложность реализации и влияние на текущую архитектуру
Оценку проводили по шкале от 1 до 3, где 3 — максимальное влияние или сложность.

После проработки low-fi концептов стало понятно, что изначальный флоу получился перегруженным. Приоритизация помогла сместить фокус на механики, которые дают максимальный эффект уже в первой итерации и при этом не усложняют интерфейс:
Режимы заполнения: массовый и по отдельности
Действия над файлами: предпросмотр, удаление, замена и тд
Контроль ошибок: по формату, размеру и лимиту загрузки
Остальные решения отложили до следующей итерации.
Тестирование ускорения флоу
После сборки дизайна первой версии нам было важно проверить, действительно ли новый интерфейс ускоряет обработку документов. Для этого я собрала интерактивный прототип с базовым happy-сценарием, в котором нужно обработать 7 документов с разными типовыми ситуациями.
Тестирование проводилось внутри команды, чтобы проверить базовый сценарий и отфильтровать очевидные проблемы до пользовательских тестов. Участвовали я, дизайн-лид, продакт, бизнес-аналитики и UX-исследователь. Каждый проходил сценарий в старой и новой версии интерфейса по 3 раза, чтобы снизить влияние случайных факторов.
В результате посчитали усредненные значения по всем замерам:
старая версия интерфейса ~2:44
новая версия интерфейса ~2:04
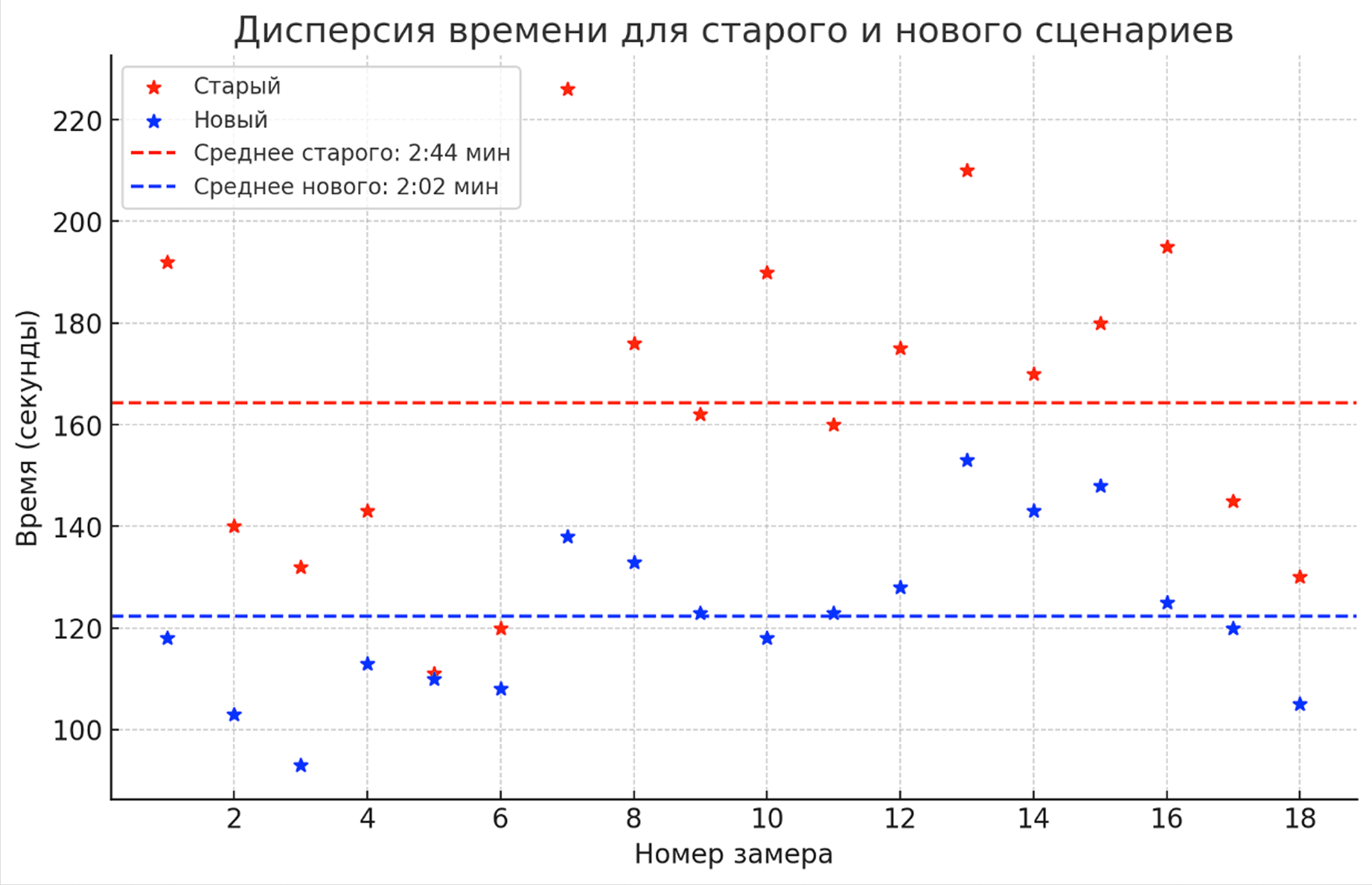
На графике видно не только снижение среднего времени, но и уменьшение разброса между замерами:
В старой версии мы чаще вспоминали, где находится нужное действие, и возвращались назад.
В новой версии результаты более стабильные за счёт единого экрана и отказа от пошаговости.
Тестирование показало, что новое решение ускоряет прохождение сценария на ~24%.
Юзабилити-тестирование
Количественный замер показал ускорение сценария, но не отвечал на вопрос, почему интерфейс стал удобнее и где остаются риски — это мы проверили на юзабилити-тестах.
Подготовка
Вместе с исследователем мы определили, какие гипотезы будем проверять. Я собрала интерактивные прототипы, а исследователь подготовила гайд для проведения тестов. Для тестов мы сфокусировались на ключевых механиках первой версии: режимах заполнения, действиях над файлами, группировке и работе с ошибками.
Что проверяем:
Как понимают логику массового и одиночного режимов, чувствуют ли контроль над вводом данных и уверенно ли переключаются между режимами.
Насколько понятно управление файлами прямо в списке: точечно и массово, без переходов на дополнительные экраны.
Насколько понятна логика группировки файлов и действий над группой, что происходит с файлами после объединения и как управлять составом группы.
Понимают ли, что происходит с файлами при ошибках загрузки и превышении лимита, и чувствуют ли они контроль над процессом.

В тестировании участвовали 10 сотрудников, знакомых со старым интерфейсом, чтобы они могли сравнивать поведение и ощущения. Отдельным квестом стало показать сотрудникам прототипы: в рабочем контуре у них был запрещён доступ к фигме. Поэтому я транслировала прототипы в TrueConf и передавала управление экраном участникам 🤷🏻♀️
Результаты тестирования
Сценарий 1. Режимы заполнения
✅ Понимают, что ввод значений относится к выделенным файлам
⚠️Понимают назначение тумблера по отдельности
Не все замечали переключение режима и хотели редактировать файлы по одному через чек-боксы
❌Понимают, что введенные значения применяются автоматически
Переживали, что значение не применилось, и ожидали явную индикацию или кнопку «Применить»
✅ Понимают, что в режиме по отдельности можно переключаться по файлам
⚠️Ожидают, что при смене режимов введённые данные сохранятся
Некоторые подумали, что значения сбросились, хотя это было отображение «разные значения»
⚠️Понимают, что означает состояние поля «разные значения»
Ожидали, что по клику можно посмотреть конкретные значения
Сценарий 2. Действия над файлами
⚠️Различают массовые и точечные действия над файлами
Многие не замечают нижнюю панель
✅Понимают как удалить и заменить файл
⚠️Понимают, как открыть предпросмотр
Ожидали открыть по клику на название или на стрелку
⚠️Понимают, как посмотреть заполненные атрибуты файла
Механика считывается, но не с 1 раза
Сценарий 3. Работа с группами файлов
✅Понимают, как сгруппировать файлы
⚠️Понимают, как посмотреть состав группы файлов
Некоторые пытались открыть группу через стрелку в строке
⚠️Понимают, что действия в контекстном меню относятся ко всей группе
Некоторые думали, что действия относятся к конкретному файлу
❌Понимают разницу между разгруппировать и отделить от группы
Путают с удалением, не понимают различие
✅ Понимают, что заполненные атрибуты группы относятся ко всем файлам в ней
✅ Понимают, что при разгруппировке можно сохранить или очистить данные
Сценарий 4. Работа над ошибками
✅Понимают, какие файлы не загрузились и по какой причине
✅Понимают, что ошибочные и лимитные файлы не блокируют работу с загруженными файлами
✅Понимают, что будет после удаления ошибочного файла
⚠️Понимают, что файлы с ошибками можно заменить
Многие воспринимали иконку замены как «обновить»
⚠️ Понимают множественные действия над ошибочными файлами
Некоторые думали, что удалятся вообще все загруженные файлы
✅ Понимают как дозагрузить файлы
Выводы
Что хорошо
Базовая логика режимов в целом считывается, механика рабочая. Действия над файлами пользователи находят быстро и чувствуют контроль. Понимают логику группировки и замечают ее ценность при работе с пачками файлов. Ошибки теперь видны, но не мешают работе и контролируемы.
Что вызвало сложности
Пользователям не хватало явной индикации применения изменений
Функционал с режимами требует небольшого онбординга
Для предпросмотра часто хотели воспользоваться дабл-кликом как в папках
Терминология и тексты в уведомлениях иногда смущали
Идеи от пользователей
Кнопка "Применить" в заполнении атрибутов
Быстрое переименование файла
Сравнение двух файлов в предпросмотре
Редактирование атрибутов в раскрытой структуре
Автогруппировка файлов с похожими именами
Предпросмотр группы по вкладкам
Итоги
Тесты показали, что новое решение действительно работает: интерфейс стал быстрее, понятнее и предсказуемее для сотрудников. По сравнению с обратной связью на прошлую версию в новой было больше положительного отклика.
Базовый сценарий обработки документов ускорился примерно на 24% — за счёт отказа от пошаговой логики, модальных окон и переходов между экранами.
Доработки по итогам тестов
Тесты показали, что ключевые сценарии не требуют изменений, поэтому я внесла минорные доработки:
добавила кнопку «Применить» в правую панель, чтобы пользователям было спокойнее за данные
доработала контекстное меню с действиями над группой файлов
доработала тексты и уведомления, чтобы снизить неоднозначность формулировок

Передача разработке
После внесения правок я довела макеты до финального состояния и подготовила user-flows для ключевых сценариев. Это помогло синхронизироваться с разработкой и аналитикой, так как интерфейс работает как единое пространство с большим количеством возможных комбинаций действий.

Что дальше?
Функционал находится в активной разработке — команда использует макеты, user-flows и спецификации. После релиза планируется:
замерить фактическое время обработки документов на реальных объёмах
замерить CSI и количество дозапросов документов от клиентов
собрать обратную связь сотрудников
вернуться к отложенным задачам из бэклога для доработки сложных сценариев и того, что предложили пользователи после тестирования, например редактирование атрибутов в раскрытой структуре
Моя роль в проекте
Я вела проект от начала до конца:
исследовала текущий процесс и боли пользователей
формировала продуктовые гипотезы и собирала low-fi концепты
проектировала интерфейс, состояния и user-flows
готовила требования и материалы для разработки
собирала кликабельные прототипы и участвовала в UX-тестировании
Совместно с командой (продакт, аналитики, исследователь, лид-дизайнер) мы приоритизировали гипотезы, проводили тестирование, прорабатывали корнер-кейсы и формировали скоуп решения.
Что я вынесла из проекта
Убирать лишнее часто полезнее, чем добавлять новое
В подобных интерфейсах легко нагородить сложные и ненужные механики, главное — вовремя остановиться
Быстрые прототипы и тесты помогают избежать дорогих ошибок на разработке
Даже точечные изменения могут заметно упростить работу пользователей, если они решают реальные боли
